의료 이미지는 전문 지식 없이는 다루기가 쉽지 않은 것 같습니다.
구글링하면 관련 개념과 구현 코드가 나오는데 쓰기가 덥고 복잡하다고 해야 할까요?
커스텀 네트워크를 구축하려다가 소를 걷어차는 듯한 데이터 전처리 도구를 찾던 중 TorchIO를 알게 되었습니다.. 간단하게 사용하기 좋을 것 같습니다.
* Nvidia에서 만든 유사 플랫폼 MONAI는 제 개인적인 의견이지만 깊이 파고들기에는 TorchIO보다 이쪽이 낫다고 생각합니다. 쓰기 귀찮을 뿐입니다.
TorchIO 공식 DOC
누르다
PyPI 다운로드 PyPI 버전 Conda 버전 Google Colab 노트북 문서 상태 테스트 상태 코드 스타일: 검정 커버리지 상태 코드 품질 유지보수 사전 커밋 Slack Twitter Twitter co…
torchio.readthedocs.io
요약
TorchIO is an open-source Python library for efficient loading, preprocessing,
augmentation and patch-based sampling of 3D medical images in deep learning, following the design of PyTorch.
It includes multiple intensity and spatial transforms for data augmentation and preprocessing.
These transforms include typical computer vision operations such as random affine transformations
and also domain-specific ones such as simulation of intensity artifacts
due to MRI magnetic field inhomogeneity (bias) or k-space motion artifacts.공식 문서의 서문과 마찬가지로 대략적인 요약은 다음과 같습니다.
– Pytorch 프레임워크를 대상으로 개발, 3D Shape 의료 영상 데이터 세트 로딩/전처리/증강 및 패치 기반 샘플링 지원
– 다중 강도(T1, T2, FLAIR?와 같은 양식과 유사) 및 데이터 증대 및 전처리를 위한 공간 변환 기술 포함
(Random Affine Transformation부터 K-space motion Artifacts/Bias Field(자기장) 불균일성 등의 기술까지..)
– 2021년 Pytorch Ecosystem & Developer Day에서 공개된 공식 Pytorch 생태계, 다양한 그룹에서 연구 목적으로 사용하고 있습니다 blah blah blah..
설치 및 예시
$ pip install torchio # --upgrade parameter(라이브러리 버전 업데이트/재설치)
$ pip install torchio(plot) # TorchIO의 plotting 관련 메소드 사용(Matplotlib)간단한 튜토리얼은 아래 링크 참조
GitHub – fepegar/torchio: 딥러닝을 위한 의료 영상 툴킷
딥 러닝을 위한 의료 영상 툴킷. GitHub에서 계정을 생성하여 fepegar/torchio 개발에 기여하십시오.
github.com
데이터 구조
크게 Image, Subject, Dataset으로 구성
1. 이미지(라벨): 이미지 및 라벨
2. 제목: 이미지와 라벨이 짝을 이룹니다.
3. Dataset: 여러 주제의 모음
자세한 설명이 있지만 이렇게 구조만 이해해도 처리하는데 큰 문제는 없었습니다.
패치 기반 파이프라인
3D 형상의 의료 영상 영상은 그 특성상 제약이 많다.
예를 들어 차원이 하나 더 추가되면 필요한 리소스가 2D 셰이프보다 훨씬 큽니다.
* RGB 2D 이미지 1개(가로 세로 256픽셀): 3x256x256
* Z축이 추가된 3D 이미지 1건(가로, 세로 + z축 256 Pixel): 1x256x256x256
분산 학습(여러 GPU) 같은 방법 없이 그대로 네트워크에 전송하면, 물론 구토
또한 경험상 각 차원별 픽셀 값이 항상 256으로 고정되는 것은 아니지만 그보다 낮거나 높은 값을 갖는 경우가 있습니다.
1의 경우 각 축에 대한 픽셀 수가 일정하지 않은 경우가 많습니다 – 176x224x256 이렇게
오픈소스 데이터셋의 경우 각 데이터의 크기가 통일되어 있지 않아 개별적으로 보기가 어렵습니다.
각 축을 잘라서 2D 형태로 학습하는 방법을 사용하지 않는 이유는 공간 정보가 중요하기 때문일까요? 라고 생각했다
따라서 이미지의 원래 크기가 아닌 일정한 크기로 자른 3D 형상, 즉 패치 단위로 나누어진 데이터를 학습한 후 결과를 병합하는 방법이 자원/추론 시간 측면에서 유리할 수 있다.
하지만 제 경험상 공간정보(수업형태든 뭐든…)는 필수로 입력해야 하는 것이 당연해 보입니다.
(특정 부분을 잘라내기 때문에 각 패치의 경계선 – Edge 면의 경우 병합 시 깔끔하게 연결되지 않는 등 부정확한 결과가 발생할 수 있습니다.)
아래는 공식 문서의 간단한 회로도입니다.
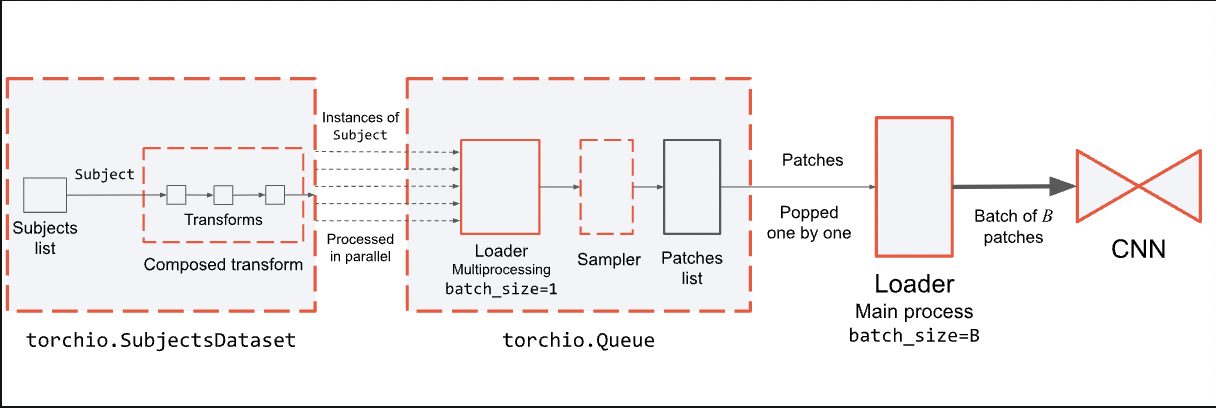
지원되는 샘플링 방식(Samplers)은 여러 종류가 있으며 크게 다음과 같습니다.
1. 유니폼 샘플러
2. 가중치 샘플러
3. 라벨 샘플러
4. 패치 샘플러
5. GridSampler(+ GridAggregator): 추론 과정에서만 사용되는 듯
변환
TorchIO를 사용하는 동안 가장 좋은 부분입니다. 꽤 유용한 처리 방법을 제공합니다.
각 메서드는 주제 또는 이미지(또는 하위 클래스) 유형입니다 – Pytorch Tensor 또는 Numpy 배열, SimpleITK, Nibabel, Typical Python Dictionary..
모든 방법은 torchio.transforms/Transform, 주로 전처리, 증강 등에서 상속됩니다.
1. 데이터 전처리
2. 데이터 증강
3. 기타
실행 가능한 코드(예제..)
글쓰기